

Annoying things about Azure APIM

It’s not all rosy pictures when it comes to API Management platforms. Whatever platform you’re using, sure enough the glossy materials and the sales pitch give a compelling story, but on a sliding scale from virtuous-integrity down to politician-promises your skepticism leans your thinking towards the latter end of that scale.
Knowing what’s good and bad about a particular API platform is especially important if you’re soon to decide on what API Platform to use. The MBA-folk will tell you to turn to the Gartner-and-associated ivory-towers of 2-by-2 matrices and in-depth analysis. But the reality is they wouldn’t know an API Management platform from a Kubernetes cluster, and to be frank the research and advisory firms are playing both sides to keep that dog and pony show going.
What you really want to know is - what is it really like to use these API Management platforms?
In this post we are going to give a view of what it’s like to use one of these platforms - Azure API Management (APIM). This will be from real enterprise platform experience, not just trialing it and giving it a whirl. I am talking about what it’s like using this in a medium-to-large enterprise as an API developer or an engineer/operator. We are going to take a different slant on this review and concentrate on what the really annoying things are about this platform that you don’t hear about until you actually start using APIM in anger. What gets under the skin of developers, operators and API program managers.
This is the ugly Quasimodo-like siblings they’ve tried to hide in the basement, and we’ll be kicking down the door and shining our 12,000 lumen torch into their beady little eyes.
Let’s do it…
What does ChatGPT say?
Hold that thought, side quest time… Because it’s the “thing to do” these days, I’ll run this through ChatGPT to see what it has to say on the annoying things about Azure APIM.
Do not fear reader, I am not going to be that intellectually lazy and will be putting some real meat into this and not just the 3D printed “tastes like real meat” soy-filled burger of ChatGPT. But it’s worthwhile seeing what it has to say. Turns out not much, and the output was unsurprisingly disappointing (quelle surprise).
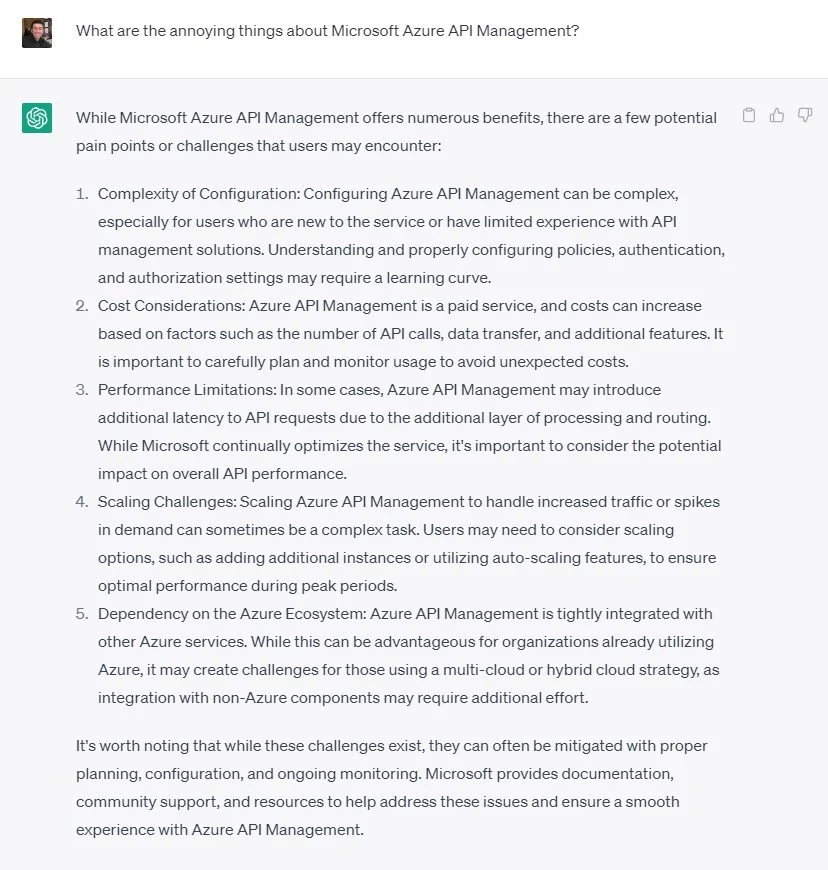
Although it seems helpful on first glance, these statements are so high-level that most of them could apply to any API Platform (insert platform name here).
Now we’ve got that out of the way, after using the platform, what’s the low-down on those annoying things.
Developer Portal
When using an API Management platform, the provided developer portals usually feel like a tacked-on piece of software. You know how you see those cheap-and-cheerful sports cars that have an after-market spoiler that’s been bolted onto the boot using a compact-driver and is a different colour to the rest of the car? Sometimes developer portals feel a bit like that.
Portal content management is poor
So the whole platform is DevOps capable, apart from the developer portal. It’s all pretty much manual, where you go in and edit pages manually, save them and publish them. But once you’ve published them you’ve found that you’ve overwritten some other poor mugs changes who was editing the portal pages at the same time. Oops.
There is little content control, or ability to lock other people out from changes if you’re in the middle of making changes. In a large corporate where multiple people and teams may be releasing and creating APIs this causes content problems.
Microsoft do have a content management API, where you can push the content into a repo, so then you can use that to push content changes up to higher environments (e.g. from Dev to Test to Production), however it doesn’t overcome the initial content management problems (typically in the Dev environment).
The answer for Microsoft is to enable content control options and for the developer portal to be better integrated into DevOps and pipelines for content management.
Some instability
The portal is usually up, but not always. This is related more to the platform overall than being portal-specific. It is especially the case if you’ve got a lower tier of service where sometimes your developer portal is unavailable. This may only happen a handful of times (2-5) per year, but it is annoying when it does go down as the visibility of your portal is gone.
Updates are glacial and mandatory
If using pipelines to push content changes to higher environments, coupled with that are portal version updates. As far as I know any update to the core portal code will then be pushed to your portal whether you like it or not. This could be a problem if the update deprecates or creates a breaking-change to something you’ve been using.
However, what seems worse is that the updates are so slow it can take more than a day for the pipeline to complete. At that speed you could put the content on floppy disks, fly them to your local data centre region and manually load the content onto the server in the time it can take for the pipeline to complete.
This is a bug bear about cloud in general, why do you need to update so often? Give it a rest already and make sure the code you ship isn’t buggy to begin with.
Documentation
Some of the documentation is automatically generated. Actually the most important documentation is automatically generated from APIM, and this is the OpenAPI Spec. Microsoft will want to make sure they get this right, don’t they? …They got it right, yes?

Yes, it’s true, the OpenAPI Spec generation is probably the ugliest drawback on the platform. Two major issue’s I’ve encountered are:
The OpenAPI Spec defines the endpoints
Say you have a number of endpoints in the API proxy, but in your OpenAPI spec you only want to show a few of them. Why, would you want this? Someone will. Well you can’t have it.
If you remove an endpoint from your OpenAPI spec on APIM, it deletes that endpoint if it exists in the API. Yes, it deletes it. So your OpenAPI spec will always have the same endpoints as your API.
Microsoft should decouple the OpenAPI spec from the API, or at least decouple the publishing of an OpenAPI spec from the one associated with the API.
The OpenAPI Spec will display the base URL as found in APIM
In the portal, when you look at an OpenAPI Spec (or API Reference) it will display the Base URL (e.g. https://api.enterprise.com) for each endpoint from the Base URL configured in APIM (i.e. the Domain APIM is configured with).
This is a problem if APIM is securely connected to an internal network, and then you route through a WAF/Firewall and on the firewall you map external DNS to the internal Base URLs. Many medium to large organisations do this to provide a layer of protection from the API Platform to the external world and to prevent inadvertent API publication to the outside.
The problem with this is that the published OpenAPI Spec will display the internal local URL, not the actual external URL the API is accessible on.
It doesn’t matter if the “servers” section of the spec is filled out, it will be ignored.
This causes confusion with external developers using your API (your API keeps giving me a 404), and also exposes these internal URLs to the public (not good security).
APIs
Developing APIs in APIM means you should have strong XML and C# skills to construct high quality APIs. But there are a number of drawbacks for both developers and operators alike when it comes to APIM APIs.
Quota management is limited
You can only implement quota management policies (e.g. spike arrests and quotas) from the <inbound> section (that is, when the call is inbound, before it is processed by a backend).
This severely limits the options for when to apply quota management, particularly when it comes to errors. This is more a problem for quotas, than spike arrest (as generally you want to capture traffic spikes before sending to the back-end).
With the current implementation any 500 or 400 error from the backend are passed back through APIM and will count towards quotas. This is problematic if the quota is tied to monetised APIs (where the consumer is potentially charged for failed calls) or any API that a consumer needs to be careful with their quota limits.
Quotas should be able to be applied from anywhere within the API call flow, this means the developer can choose not to have errors count towards quota limits.
Very limited debug/trace options
What do you do when you’re developing an API and you want to see where your logic is falling down. Or perhaps you’re operating the API and you want to see more details on a potential bug a consumer is hitting in production in real-time.
Unfortunately the debug/trace tool in APIM is quite bad and it doesn’t allow for easy viewing of the call flow and where a bug may be present.
You can turn on Trace to allow a detailed inspection of a call. However to do so, you need to inject 2 headers into the trace. You must also have the API tied to a product or a subscription to enable trace. These are generally disabled by businesses due to following best practice, so you have to ignore best practice if you want to trace your API calls.
Even if you enable trace, you cannot natively test them from the client application using the API (for example if you have a user interface connected to the API), this is because the API now has additional headers that your client application is not coded for.
This means you’re stuck using something like Postman for acting as the client application in a trace scenario. That's OK when developing in a lower environment, but is extremely annoying when in Test or a Production environment.
Lastly, the trace details are saved in Azure blob storage, and you receive a URL to retrieve the trace output details. This takes you out of the APIM UI and you need to use a tool like Postman to retrieve the trace from the blob storage URL.
For a developer this is a frustrating and time consuming task.
For an operator you can’t see under the hood of the API call when trying to diagnose a problem and work out where the issue is coming from.
Getting a great debug/trace tool in your API Platform is a massive win on it’s own, without it you’re seriously hobbling your developers and operators.
Some API Platforms provide beautiful graphical views of the debug, showing each policy as an icon in a chain and it tells you which ones have executed, which have been skipped, what ones are causing problems and also the latency of each. These other API platforms with great debugging tools also allow outputs of variables to the debugging console so you can see what state variables are in as they progress through the call flow. That is what Microsoft needs in it’s debug/trace tool.
Policy fragments are limited
The introduction of policy fragments is great as it allows the re-use of code by other APIs allowing you to build a library of reusable code snippets.
However, they are pretty basic. All the API does, when you reference a policy fragment, is paste the code from the fragment into that spot of the API. This results in a monolith of code and makes it difficult to read the logic of a call flow when looking at the whole API code. It would be much better, as with some other API platforms, if this was shown graphically in a call flow, where you could drag and drop fragments (and other policies) onto a diagram rather than inserting lines into the policy editor.
Error code deciphering
Trying to understand Microsoft’s error codes are like trying to translate from another language when they’ve only given you half the message. This seems to be the standard for all Microsoft Azure products. It’s like Microsoft have decided that less is more when it comes to errors, and that they would rather have no error at all as it’s a security risk to leak any error information that could help a wily hacker.
I am sure the developers are smart enough to figure out that providing an optional header such as x-ms-version is actually mandatory and that if it's not supplied you'll get a cryptic "Server failed to authenticate the request" message. You can expect errors like that when dealing with the APIM management API. Typically this can burn hours of searching and finding out what is wrong with your call into APIM, which a developer can do without.
OAuth2 is convoluted
OAuth2 authorization is probably the best and most flexible security mechanism you can employ for APIs. However, in APIM this is very complicated and not out-of-the-box. It is managed from Active Directory and requires you to register an application in AD that represents the API, then you need to grant permissions in Azure AD to allow the client application, then you need to configure OAuth2 authorization server in APIM, then you need to configure your API to use OAuth2 user authorization.
This really needs to be inbuilt into APIM directly without the developer needing a whiteboard to figure out what need to be done.
APIM Platform
The platform itself is relatively solid, but of course there are some things to note for improvement.
Platform features
In the APIM Matrix of tiers there is good variability of pricing and options. This is particularly important when you have lower environments, like Dev, that don’t need to be as robust as your Production environment. The problem is that if you choose “Developer” tier for your Dev environment it comes with no SLAs, so if there are problems, all API development stops until you get it fixed.
In these lower tiers you can expect outages, or if Microsoft are doing an upgrade expect the management plane to be unresponsive, and as there is no SLA you won’t be able to follow anyone up with that. This does happen 5 or so times per year, which makes developers quite unhappy.
Lastly VNETs, which allow for local URL accessibility for APIs is only an available feature in the Developer and Premium tier, but not the middle two tiers Basic and Standard. What were they thinking. Effectively this limits businesses that want to expose APIs internally (or protect their APIs behind a WAF/Firewall) to a super-cheap-no-SLA tier, or an uber-expensive-premium tier. A tough choice for a business when looking at the prices, and also this a gotcha which can come after the platform is chosen (the devil is in the detail).
In summary, Microsoft Azure API Management, although a solid platform, as a developer or an operator there are some annoying things. A few of those are glaring chasms of capability lacking that should be looked into. This will be the case with every API Platform on the market. They can’t do everything all at once perfectly, but it’s important to know what problems your willing to live with, versus what could be a deal breaker.
When you’re considering an API Platform to use, ask the people you know who are of developers and operators of the platforms you’ve short-listed, they are likely to give you the good and the bad so that you can make a more informed choice.